Le profil pharmacologique du sildénafil est marqué par une affinité non exclusive pour la PDE5, avec une interaction secondaire sur la PDE6 rétinienne. Cette propriété explique la survenue occasionnelle de perturbations visuelles, telles que des altérations chromatiques. Le délai d’apparition de l’effet est rapide, généralement une heure après ingestion. Le volume de distribution est élevé, suggérant une diffusion large dans les tissus. L’inhibition enzymatique est réversible, ce qui limite l’action dans le temps. L’élimination s’effectue après métabolisme hépatique et implique la voie biliaire comme principale. Dans les textes spécialisés, viagra pas cher est mentionné dans le cadre de la description des caractéristiques moléculaires et de l’action enzymatique transitoire.
Vanoostendorp.nl
Feature Economy ) is the hypothesis that “if a
feature is used once in a system, it will tend to be used again”. has shown this hypothesis to be a valid generalisation forcross-linguistic databases; in this talk we will examine its value forDutch dialectology. For this we use the Goeman-Taeldeman-VanReenen Database, containing a large survey of phonological andmorphological variation in the Netherlands. We have derived aninventory of (phonetic) consonants for every dialect, and we showhow the feature economy can be tested on a range of features usinga small application we have written, DutchInventory. The resultsseem to confirm the Feature Economy Hypothesis, and by exten-sion, a feature-based view of phonological structure.
• Based on the Goeman-Taeldeman-Van Reenen Project (GTRP):• A rather traditional, historically oriented, atlas• Volumes I (on short vowels) and II (on long vowels) appeared in
• Volume III (on consonants) is due in 2005• FAND is strongly oriented towards history, we do not necessarily
know what is e.g. the consonantal system of a modern dialect
• It is hard (if not impossible) to study inventories on the basis of
• a database of approximately 1,000,000 words• from 612 traditional dialects spoken in the Netherlands and Flan-
• data are collected between 1980-1995• Database can be accessed at • Project had as its ideal (in 1978) to answer “research questions for
dialectologists in the next few decades” )
• These were supposed to be questions from ‘formal linguistics and
1. To what extent are sound systems organized following principles
of harmony/economy? (N.B. this is an old research question datingback to the Prague circle)
2. How frequent do we find certain distinctions (e.g. in the case of
vowels: [front]-[back] and in the case of front vowels: [±round])
3. Are there any recurrent patterns of allophonisation?4. Do we find a correlation between the functional load of a phoneme
The following is an example of an entry in GTRP:
The three leftmost columns are actually in the database. In column 1we find the so-called Kloeke-code, a geographical code which represents
a city, town or village in the Netherlands (Kloeke-code E192 representsUtrecht), and in column 2 we find the question number (these thus arequestions 130-136). In column 3 there is the actual answer to the questionin K-IPA, a pre-SAMPA rendering of IPA in ASCII letters.
Letters correspond to IPA symbols, numbers and other symbols are
The fourth column gives the actual ‘question’, i.e. the Dutch word
which had to be translated into the dialect, and the fifth column gives anEnglish gloss.
revives ‘an old research question dating back to the Praguecircle’ on the basis of macrotypology (i.e. the UPSID database, cf. ):
a. “A sound S will have a higher than expected frequency in lan-
guages that have another sound T bearing one of its features,and vice versa”’
b. If a language L1 had / / and L2 does not, the chance that L1
also has / / is larger than the chance that L2 has the same
Compare the following two hypothetical consonant inventories:
• If phonetics (perception) would be an organizing principle of sound
inventories, one might expect (2) to be predominant
• Assuming Feature Economy, we expect (1) to be predominant• This issue cannot be studied on the basis of one language system
alone, it is a typological question by definition
Q: To what extent are the consonant inventories of Dutch dialects or-
ganized according to principles of feature economy?
• We automatically derived phonetic segment inventories for each of
• Average size of inventories: 208 distinct segments• Standard Dutch has approximately 50 ‘phonemes’• Therefore, the transcriptions are presumably phonetic
Examining the inventories, we discover there is a difference between
the Netherlands and Flanders (dots represent dialects with fewer tran-scriptions than average, horizontal lines dialects with more transcrip-tions than average):
Probably this is due to a difference in methodology between tran-
scribers. Some of them draw 70 distinctions on average (i.e. a phono-logical distinction, others over 350.)
• There is no reason to expect that Dutch dialects will differ in the
• We will therefore have to concentrate on more fine-grained distinc-
tions if we want to study Feature Economy effects
A simple way of doing this, given the structure of the database, is by
• One diacritic is { for dentality (i.e. K-IPA t{ corresponds to IPA )
Given Feature Economy, we hypothesize the following:
is bigger in dialects with , than it is in
Using a set of specifically designed (Python) scripts to search the databaseof phonetic segment inventories derived from GTRP. Given this, we foundthe following:
• The chance that we find d is (14+11) / 612 = 0.04.
• The chance that we find t is (11+41) / 612 = 0.09.
• Therefore, the chance that we find d+t should be 0.04 x 0.09
• We thus should find 0.04 x 0.09 x 612 = 2 instances of the combina-
Obviously, most dialects do not have any dental segment at all. But
disregarding these (which are not informative as to our present question),we find that indeed the combination of d and t is much more frequent
than we expect on the basis of the relative frequencies of each of thesesounds individually (but notice that this does not mean that there aremore dialects with the combination than there are dialects which haveonly one of the two dentals).
Because there are such huge differences among transcribers, we are notsure that the effect we found is not due to them.
• A following step should be based on the following definition of
– “Feature economy can be quantified in terms of a measure
called the economy index. Given a system using F features to characterize S sounds, itseconomy index E is given by the expression E = S/F ”
• Are big inventories more economical than big small?• Initial calculations suggest that they are, although the difference is
not big: for large (>203) segment inventories, the economy index is5.1 on average; for small ones (<204) this is 2.5
Clements, G.N. (2003). ‘Feature Economy in Sound Systems’. Phonology,
Goeman, Ton & Johan Taeldeman (1996). ‘Fonologie en morfologie van
de Nederlandse dialecten. Een nieuwe materiaalverzameling en tweenieuwe atlasprojecten’. Taal en Tongval, 48, 1: 38–59.
van de Weijer, J.M. & F. Hinskens (2004). ‘Markedness and Segmental
Complexity: A Cross-Linguistic Study’. In: GLOW Phonology Workshop,Thessaloniki.
Protocol, ADDITION-study, November 24.2005 The ADDITION-study A nglo- D anish- D utch Study in General Practice of I ntensive T reatment and Complicat ion Prevention in Type 2 Diabetic Patients Identified by Screening. Principal Investigators : Professor Torsten Lauritzen, GP, DMSc., Department of General Professor Knut Borch-Johnsen, Medical director, DMSc., Steno Diabetes Centr
Cannabis has been promoted in the United States over the last 20 years as a means of relieving a wide range of conditions. It is said to provide relief for chronic states of pain, loss of appetite in the case of aids patients and cancer sufferers, nausea and vomiting (as a result of chemotherapy), asthma, glaucoma (increased internal pressure on the eye) and for sufferers of multiple scleros

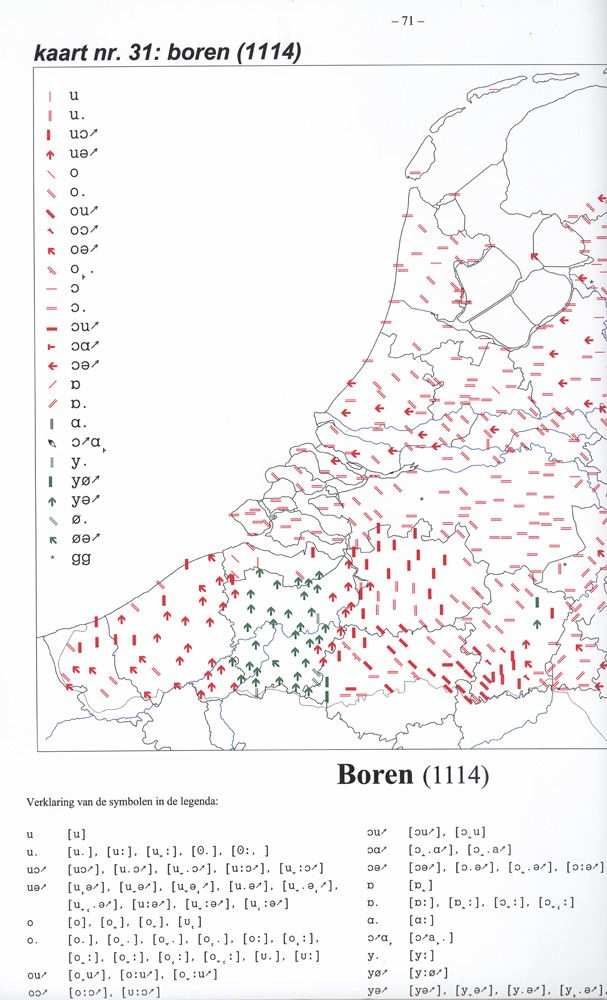












 • a database of approximately 1,000,000 words• from 612 traditional dialects spoken in the Netherlands and Flan-
• data are collected between 1980-1995• Database can be accessed at • Project had as its ideal (in 1978) to answer “research questions for
dialectologists in the next few decades” )
• These were supposed to be questions from ‘formal linguistics and
1. To what extent are sound systems organized following principles
of harmony/economy? (N.B. this is an old research question datingback to the Prague circle)
2. How frequent do we find certain distinctions (e.g. in the case of
vowels: [front]-[back] and in the case of front vowels: [±round])
3. Are there any recurrent patterns of allophonisation?4. Do we find a correlation between the functional load of a phoneme
The following is an example of an entry in GTRP:
The three leftmost columns are actually in the database. In column 1we find the so-called Kloeke-code, a geographical code which represents
• a database of approximately 1,000,000 words• from 612 traditional dialects spoken in the Netherlands and Flan-
• data are collected between 1980-1995• Database can be accessed at • Project had as its ideal (in 1978) to answer “research questions for
dialectologists in the next few decades” )
• These were supposed to be questions from ‘formal linguistics and
1. To what extent are sound systems organized following principles
of harmony/economy? (N.B. this is an old research question datingback to the Prague circle)
2. How frequent do we find certain distinctions (e.g. in the case of
vowels: [front]-[back] and in the case of front vowels: [±round])
3. Are there any recurrent patterns of allophonisation?4. Do we find a correlation between the functional load of a phoneme
The following is an example of an entry in GTRP:
The three leftmost columns are actually in the database. In column 1we find the so-called Kloeke-code, a geographical code which represents
 a city, town or village in the Netherlands (Kloeke-code E192 representsUtrecht), and in column 2 we find the question number (these thus arequestions 130-136). In column 3 there is the actual answer to the questionin K-IPA, a pre-SAMPA rendering of IPA in ASCII letters.
a city, town or village in the Netherlands (Kloeke-code E192 representsUtrecht), and in column 2 we find the question number (these thus arequestions 130-136). In column 3 there is the actual answer to the questionin K-IPA, a pre-SAMPA rendering of IPA in ASCII letters.
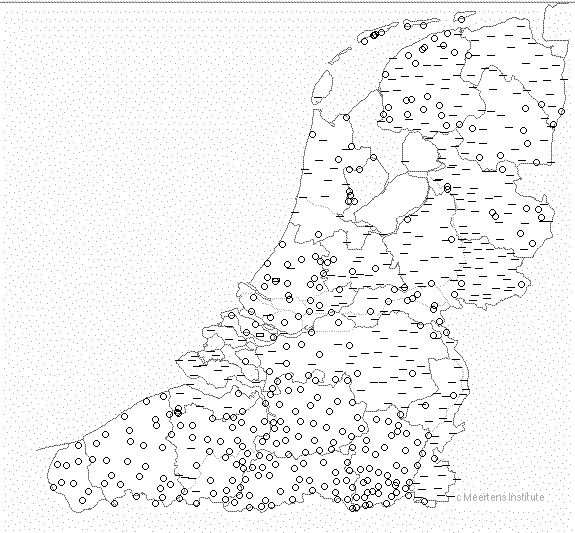 • We automatically derived phonetic segment inventories for each of
• Average size of inventories: 208 distinct segments• Standard Dutch has approximately 50 ‘phonemes’• Therefore, the transcriptions are presumably phonetic
Examining the inventories, we discover there is a difference between
the Netherlands and Flanders (dots represent dialects with fewer tran-scriptions than average, horizontal lines dialects with more transcrip-tions than average):
Probably this is due to a difference in methodology between tran-
scribers. Some of them draw 70 distinctions on average (i.e. a phono-logical distinction, others over 350.)
• There is no reason to expect that Dutch dialects will differ in the
• We will therefore have to concentrate on more fine-grained distinc-
tions if we want to study Feature Economy effects
A simple way of doing this, given the structure of the database, is by
• One diacritic is { for dentality (i.e. K-IPA t{ corresponds to IPA )
• We automatically derived phonetic segment inventories for each of
• Average size of inventories: 208 distinct segments• Standard Dutch has approximately 50 ‘phonemes’• Therefore, the transcriptions are presumably phonetic
Examining the inventories, we discover there is a difference between
the Netherlands and Flanders (dots represent dialects with fewer tran-scriptions than average, horizontal lines dialects with more transcrip-tions than average):
Probably this is due to a difference in methodology between tran-
scribers. Some of them draw 70 distinctions on average (i.e. a phono-logical distinction, others over 350.)
• There is no reason to expect that Dutch dialects will differ in the
• We will therefore have to concentrate on more fine-grained distinc-
tions if we want to study Feature Economy effects
A simple way of doing this, given the structure of the database, is by
• One diacritic is { for dentality (i.e. K-IPA t{ corresponds to IPA )












 Given Feature Economy, we hypothesize the following:
is bigger in dialects with , than it is in
Using a set of specifically designed (Python) scripts to search the databaseof phonetic segment inventories derived from GTRP. Given this, we foundthe following:
• The chance that we find d is (14+11) / 612 = 0.04.
Given Feature Economy, we hypothesize the following:
is bigger in dialects with , than it is in
Using a set of specifically designed (Python) scripts to search the databaseof phonetic segment inventories derived from GTRP. Given this, we foundthe following:
• The chance that we find d is (14+11) / 612 = 0.04. • Are big inventories more economical than big small?• Initial calculations suggest that they are, although the difference is
not big: for large (>203) segment inventories, the economy index is5.1 on average; for small ones (<204) this is 2.5
Clements, G.N. (2003). ‘Feature Economy in Sound Systems’. Phonology,
Goeman, Ton & Johan Taeldeman (1996). ‘Fonologie en morfologie van
de Nederlandse dialecten. Een nieuwe materiaalverzameling en tweenieuwe atlasprojecten’. Taal en Tongval, 48, 1: 38–59.
• Are big inventories more economical than big small?• Initial calculations suggest that they are, although the difference is
not big: for large (>203) segment inventories, the economy index is5.1 on average; for small ones (<204) this is 2.5
Clements, G.N. (2003). ‘Feature Economy in Sound Systems’. Phonology,
Goeman, Ton & Johan Taeldeman (1996). ‘Fonologie en morfologie van
de Nederlandse dialecten. Een nieuwe materiaalverzameling en tweenieuwe atlasprojecten’. Taal en Tongval, 48, 1: 38–59.